
Published on: Nov 10, 2024
MySQL performance optimization techniques
MySQL is the top 2 most used RDBMS for production. It scales well vertically for small-medium-size databases. The default configuration that MySQL comes with works well for only the initial stages of deployment. For deploying in production, the default settings must be tuned for better performance. Other than the parameters/settings, we also need to take care of how we handle/interact with the MySQL like query optimization, indexes, connection pool, etc.
This blog goes through some of the most important configurations that need to be looked at, which improve MySQL performance by multiplefold with fewer settings.
DB size
First, check the total DB data size to better understand the type of improvements and tuning to apply to various parameters.
- total DB size (both data and index size):
1SELECT ROUND(SUM(data_length + index_length) / 1024 / 1024, 2) AS "Size (MB)" 2FROM information_schema.TABLES; 3
- by each database:
1SELECT table_schema AS "Database", ROUND(SUM(data_length + index_length) / 1024 / 1024, 2) AS "Size (MB)" 2FROM information_schema.TABLES 3GROUP BY table_schema; 4
- by table in database_name:
1SELECT table_name AS "Table", ROUND(((data_length + index_length) / 1024/ 1024), 2) AS "Size (MB)" 2FROM information_schema.TABLES 3WHERE table_schema = "database_name" 4ORDER BY (data_length + index_length) DESC; 5
InnoDB Architecture
It is crucial to understand the InnoDB architecture and how it saves data into memory because configuring InnoDB related parameters like innodb_buffer_pool_size results in boosted performance. The high-level architectural components of InnoDB we are interested in are:
- Tablespace & Data Pages
- InnoDB buffer pool
- Dublewrite buffer
- Undo Log
- Redo Log
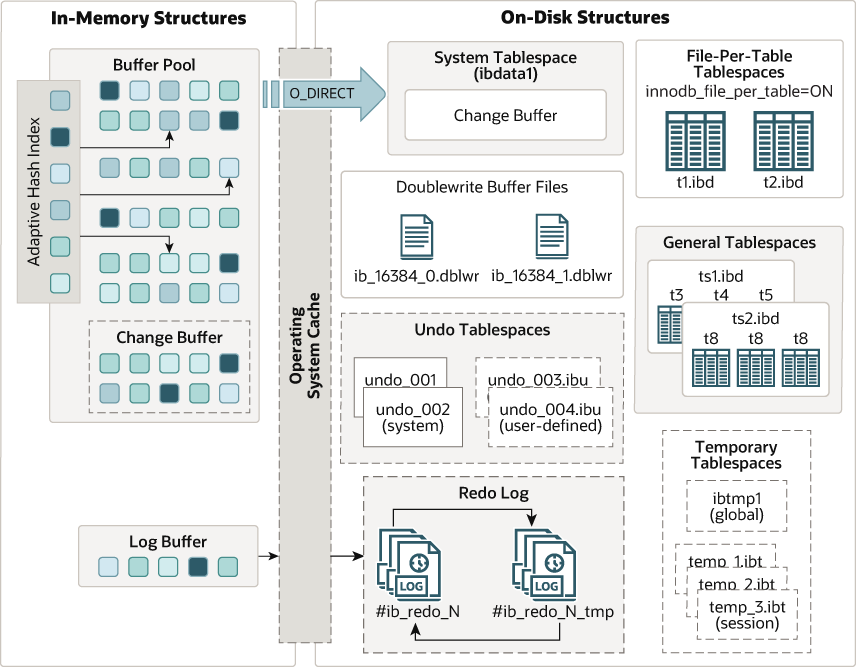
Data is stored in tables as data pages under tablespace generally with a file-per-table mode in harddisk. Reading the pages from the disk for every operation adds latency and MySQL can't serve multiple requests concurrently. So, InnoDB reads the data pages and loads them into a buffer in memory (RAM) for fast access called Buffer Pool. The larger the buffer pool size, the more read hits the InnoDB can get from this buffer cache. So, it is crucial to allocate more buffer pool memory. Generally, 50-75% of memory is recommended to allocate for the buffer pool. InnoDB first checks if the data page is available in the buffer pool, if not it loads them to memory. To clean up the space for newer pages, InnoDB removes the pages based on the LRU method.
The buffer pool is all about optimizing reads faster. If any write happens to those pages in the memory, instead of writing them directly to the disk, changes happen to the pages in the buffer pool itself. This is to save the time for I/O operations.
Regarding writes, any write operation is first recorded in the Redo Log buffer as Write-ahead Log for recovery and backup purposes. After writing to the log buffer has become a success then only the transactions happen to the data pages in the buffer pool. So, when the crash happens, InnoDB can redo the un-committed transactions by reading through these Redo Logs. Logs are stored in the buffer and later flushed to disk.
Any transaction writes are first stored in Undo Log where it stores the before-data of the affected rows of the transactions. This is also used for transaction rollback or crash recovery when the system crashes while performing any transactions or simply to undo the transaction changes. When multiple connections read the same data that another connection is locked in, they all see the before data stored in the undo logs.
Data pages in the buffer that are changing due to transactions are called Dirty Pages and are flushed to actual disk storage later when the checkpoint happens. InnoDB uses fuzzy checkpoints rather than static/fixed checkpoint intervals to flush the pages. Fuzzy checkpoint means instead of stopping the new transactions record for flushing the data synchronously, analyze and find the dirty pages and flush them asynchronously in the background without stopping new transactions.
For recovery purposes, data is first synced to Doublewrite buffer in the disk and then directly in tablespace files. This is because, after the crash, InnoDB checks the data in this double-write buffer and the actual data, and syncs them by each page. The operations needed to perform for actual data sync are more than simply writing the pages to the double-write buffer. So, it is faster and the pages are flushed to buffer in batches rather than file-by-file.
Ref:
- https://www.alibabacloud.com/blog/mysql-memory-allocation-and-management-part-ii_600992
- https://hidetatz.medium.com/how-innodb-writes-data-on-the-disk-1b109a8a8d14
- https://www.percona.com/blog/understanding-the-differences-between-innodb-undo-log-and-redo-log/
- https://www.alibabacloud.com/blog/what-are-the-differences-and-functions-of-the-redo-log-undo-log-and-binlog-in-mysql_598035
Innodb buffer pool hit ratio check
Show InnoDB buffer present config
1SHOW engine innodb status; 2
Get buffer pool size(bytes)
1SELECT ROUND(@@innodb_buffer_pool_size / 1024 / 1024 / 1024, 2) AS "Buffer pool size (GB)"; 2
Get pages read and read requests from the buffer pool
1SELECT variable_name, variable_value from sys.metrics 2WHERE variable_name IN ('innodb_pages_read', 'innodb_buffer_pool_read_requests'); 3
If the hit ratio is not close to 100% then increase the buffer pool size to allow the maximum DB data to fit but within memory requirements.
Query optimization
Use explain, analyze, and format= to analyze the query breakdown steps, indexes used, and operations performed to get a hold on where we can improve the query processing by adding necessary indexes, dropping unnecessary conditions, re-ordering query steps, and other bottleneck steps.
- Check the query optimization plan
- Add indexes like composite index and covering index to completely cover all columns in the query for super fast lookup
- Re-write query as a SARGABLE(Search ARGument ABLE) query which utilizes the index for quick searching instead of working on each row
- Avoid functions and calculations on index columns in the query as these will apply for each row
- For function-based where clause, create a function-based index on the column
- Limit the amount of data rows that need to be sorted by better query execution planning
- Rewrite JOINs into a subqueries sometimes gives better results
- Order of execution: FROM, JOIN, WHERE, GROUP BY, HAVING, SELECT, ORDER BY, LIMIT
Indexes in MySQL
Every table should have a primary key. If a primary key is not defined, then InnoDB uses the first unique non-null column as the primary key. If no such column exists, InnoDB creates a hidden row incremental key for the primary key.
Some of the trade-offs to consider are
- Sequential vs Non-sequential primary key
- Clustered vs Non-clustered index
- Single-level index vs Composite indexes (and Covering index)
- Single-level index vs Column order index
If there are redundant indexes, then write operations takes time, check and remove the redundant indexes
1select * from sys.schema_redundant_indexes; 2
Also, check how much memory an index takes, and if it is not in acceptable levels, drop that index and change the schema for better performance.
Connection Pool
- A DB connection comprises opening the tcp socket, acknowledgement, authentication, authorization, network session creation, etc. So, it takes time to open a new connection every time. So maintain a pool of connections to re-use.
- By default, the max_open_connections a MySQL server can handle is 150, but can be set up to 2^32 (but up to 100,000 should be the limit generally).
- Types of connection pooling:
- Session: Maintain connection until the session completes. The client can make any number of transactions until connection timeout is reached.
- Transaction: Connection is returned to the pool when the transaction completes.
- Statement: A connection is used only for a single SQL statement.
- Generally, max_pool_size (max_active_connections) is set to (2 or 4 * no.of cores), but it varies depending on the type of application and the traffic.
- For normal setup, max_idle_connections (ex: 80) will be less than max_pool_size (ex: 100, and 20 connections will be closed after use as the max idle connections are 80).
- For high concurrent systems, set the max_idle_connections the same as the max_pool_size, idle connections take some memory but it's a trade-off compared to the overhead of opening connections for highly frequent requests.
Scaling challenges
- Max open connections, idle connections, and pool size should be limited considering the system resources limit.
- System resources like memory, CPU cache, and data storage are required if there are more connections opened at a time. If the system can't handle more connections, all operations will be rejected and that leads to data inconsistency.
- In Linux servers, the ulimit restricts the max open file descriptors.
- MySQL is multi-threaded and allocates one thread per connection which requires thread management overhead along with system resources.
- Configuration variables like thread_cache_size ( defaults to 8-100, and multiplexed to cores) which defines how many threads can be cached for re-use when the client disconnects. This also requires additional memory but improves performance.
- MySQL creates a THD (Thread Handle Descriptor) for each connection with a minimum memory of ~10KB and can grow to ~10MB for average connection when executing queries. So, handling huge no.of parallel connections requires huge memory requirements and also high thrashing.
- As more no.of connections increases but the max_connections are set in limit which are nothing but user threads, there has to be a balance between the user thread-per-core ratio (max ratio recommended is ~4) and the latency. So, based on this, the transactions-per-second (TPS) the server can handle can be determined, and has to scale the DB for the expected load.
- Another important challenge is the underlying disk storage. If there is huge data stored, the user threads spend most of the time for data to arrive from disk. So, better disk storage mechanism has to be considered like SSDs, cache, read/write heavy disks, etc.
- In MySQL thread pool (enterprise edition), correctly tuning the thread_pool_size and max_transaction_limit for high concurrency is very difficult but it's better than the default thread handling mechanism.
Ref:
- https://dev.mysql.com/blog-archive/mysql-connection-handling-and-scaling/
- https://dev.mysql.com/blog-archive/the-new-mysql-thread-pool/
- https://dev.to/dbvismarketing/a-guide-to-multithreading-in-sql-3hh1
Transactions Isolation
In high concurrent transaction systems, it is important to isolate the transactions for data consistency. so, when multiple connections try to change the same data, how can transaction isolation be maintained so that the following problems can be avoided?
- Dirty Reads: A query in a transaction may return inconsistent data due to uncommitted changes in other transactions.
- Non-repeatable Reads: The same query in a transaction reads different data rows if executed multiple times. This may happen due to other transactions committed to the changes.
- Phantom Reads: The data rows returned by the select statements differ within the same transaction as another transaction might have inserted new rows.
The following isolation levels can be set in MySQL for transaction isolation:
- Read Uncommitted: Transactions see other transactions' un-committed changes that may cause data inconsistencies. Suitable for highly frequent updates where accuracy/consistency is not critical. Ex: Dashboards, Analytics. Solves: None
- Read Committed: Transactions see other transactions changes only if they are committed. Consistent data but anything can happen between transactions. Suitable for both highly frequent and data-consistent scenarios. Ex: Banking, reservations. Solves: Dirty Reads.
- Repeatable Read: A transaction sees the same snapshot of data throughout the life cycle and is unaffected by other transactions. Default in MySQL with InnoDB's MVCC(Multi-Version Concurrency Control). Suitable for data-consistent systems where performance can be compromised. Ex: General Web services. Solves Dirty Reads, Non-Repeatable Reads
- Serialization: Transactions lock the rows restricting other transactions to wait until completion. Suitable for high data consistent systems. Ex: Financial services. Solves: Dirty Reads, Non-repeatable Reads, Phantom Reads.
So, based on the type of requirements, set the isolation level for high concurrent database transactions.
Ref:
- https://planetscale.com/blog/mysql-isolation-levels-and-how-they-work
- https://dev.to/eyo000000/a-straightforward-guide-for-mysql-locks-56i1
- https://simon-ninon.medium.com/dont-break-production-learn-about-mysql-locks-297671ec8e73
MySQL Monitoring
MySQL can handle high concurrent traffic with a single instance if it is deployed with high CPU cores, fast access storage (SSD), and high RAM. Some of the variables to look out for monitoring are
- max_connections
- table_open_cache
- threads_connected
- threads_running
- thread_cache_size
- innodb_buffer_pool_size
Also, monitor the status variables like
- Com_select, Com_insert, Com_update, Com_delete
- status_queries
- max_used_connections
Check the reads and writes for a table with index used or not. Read count increases even without any operations also due to various reasons like background processes, cache eviction, etc., So these are not very accurate but give the proportion of operations that MySQL performs.
1select object_schema, object_name, count_read, count_write, index_name 2from performance_schema.table_io_waits_summary_by_index_usage 3order by count_read+count_write desc limit 5; 4
Check the max percentage of concurrent connections at a time relative to max connections. If the value touches >95%, then increase the max_connections value.
1100 * threads_connected / max_connections 2
Tune the following for better performance
- Increase the max_connections and thread_cache_size for handling high concurrent connections with reuse.
- Increase the innodb_buffer_pool_size for more cached data and less time for the server to read from the disk.
- Monitor the p99 which measures the latency of 99% of all transactions and check if that latency is within the defined limits.
MySQL configuration parameters
Having discussed the various topics and internals of MySQL, the following are some of the important parameters that affect the MySQL performance. As the list is very large, I have just mentioned the names and they require separate discussion deeply.
- default-character-set = utf8mb4
- max_connections
- max_user_connections, max_allowed_packet, for limiting DDoS attacks
- innodb_change_buffering
- innodb_buffer_pool_size
- innodb_buffer_pool_instances, if innodb_buffer_pool_size is more than 1GB set multiple instances
- innodb_lru_scan_depth
- innodb_io_capacity, innodb_io_capacity_max
- innodb_max_dirty_pages_pct
- innodb_flush_neighbors
- innodb_read_io_threads, innodb_write_io_threads
- innodb_flush_log_at_trx_commit, 1 is the default for ACID compliance. 0 or 2 for fast writes. For master keep it as 1.
- innodb_log_buffer_size
- innodb_log_file_size, innodb_log_files_in_group, increase these for write-heavy, for read-heavy these are not important
- innodb_flush_method, for SSD set value as O_DIRECT
- innodb_adaptive_flushing
- innodb_stats_on_metadata
- innodb_doublewrite
- innodb_purge_threads
- innodb_thread_concurrency
- innodb_parallel_read_threads
- thread_cache_size
- have_query_cache, disable for read-heavy production
- wait_timeout, interactive_timeout
- sort_buffer_size, read_rnd_buffer_size, join_buffer_size
- performance_schema, disable if not needed
- max_prepared_stmt_count, restrict to limit memory leaks
- tmp_table_size, max_heap_table_size
- table_open_cache, should be higher than opened_tables
- table_open_cache_instances, table_definition_cache
- slow_query_log, log_query_time
For better performance, monitor the following things continuously
- QPS (queries per second) under load
- Max concurrent connections at peak
- Read/write ratio to enhance the performance by replicas/partitions
- Buffer pool hit ratio
- No.of I/O operations under load
- CPU load with I/O wait time
- p99 or p95 latency
Ref:
- https://github.com/major/MySQLTuner-perl/blob/master/INTERNALS.md
- https://www.percona.com/blog/mysql-101-parameters-to-tune-for-mysql-performance/
- https://www.woktron.com/secure/knowledgebase/272/How-to-optimize-MySQL-performance.html
- https://www.red-gate.com/simple-talk/databases/mysql/optimizing-my-cnf-for-mysql-performance/
- https://releem.com/docs/mysql-performance-parameters
- https://blog.searce.com/fewer-cpu-cores-will-blockyour-database-iops-in-gcp-b817b8cb8af2
- https://blog.searce.com/how-max-prepared-stmt-count-bring-down-the-production-mysql-system-6ca28e577663
- https://tanishiking24.hatenablog.com/entry/innodb-durability