
Published on: May 24, 2024
Doppalf: RAG-powered fullstack AI chatbot like ChatGPT
I have built an end-to-end full-stack AI chatbot web application like ChatGPT. It's powered with RAG (Retrieval Augmentation Generation) to give LLM my personality. Meaning, that LLM will behave like me and assume the character of Lakshmi Narayana. I have built this application with LLamaindex, Cohere AI, and the Qdrant database. The full tech stack is:
- Docker
- Nginx
- UI:
- Next.js (v14)
- Typescript
- Tailwind CSS
- Backend:
- Python (v3.12)
- FastAPI
- Llamaindex
- Cohere AI
- Qdrant Cloud
 Doppalf AI streaming response
Doppalf AI streaming response
Architecture
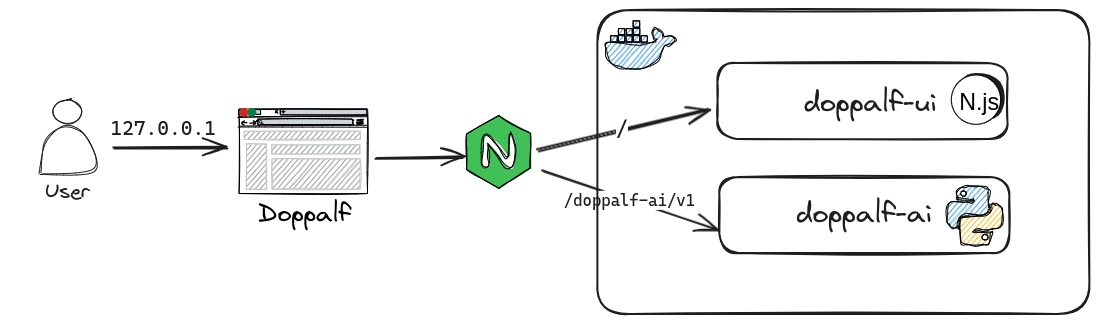 Doppalf High level Architecture
Doppalf High level Architecture
The whole project code can be found on GitHub for Doppalf.
For Doppalf, Docker has been used for container orchestration and Nginx as a reverse proxy. This application has a total three services (repos):
- doppalf-rp (Nginx)
- doppalf-ui (Next.js)
- doppalf-ai (Python)
Each of the above repos has an individual Dockerfile with optimized configuration. The following are the Dockerfiles for individual services:
doppalf-ui (Next.js)
Dockerfile
1FROM node:21-bullseye-slim AS deps 2WORKDIR /app 3COPY package*.json ./ 4EXPOSE 3001 5ENV PORT 3001 6ENV HOSTNAME "0.0.0.0" 7RUN npm ci 8 9# Development 10From deps as dev 11ENV NODE_ENV=development 12COPY . . 13CMD ["npm", "run", "dev"] 14 15FROM node:21-bullseye-slim AS builder 16WORKDIR /app 17COPY --from=deps /app/node_modules ./node_modules 18COPY . . 19RUN npm run build 20RUN npm prune --production 21 22# Production 23FROM node:21-bullseye-slim AS prod 24WORKDIR /app 25ENV NODE_ENV production 26# Add nextjs user 27RUN addgroup --system --gid 1001 nodejs 28RUN adduser --system --uid 1001 nextjs 29# Set the permission for prerender cache 30RUN mkdir .next 31RUN chown nextjs:nodejs .next 32USER nextjs 33# Automatically leverage output traces to reduce image size 34COPY --from=builder --chown=nextjs:nodejs /app/.next/static ./.next/static 35COPY --from=builder --chown=nextjs:nodejs /app/public ./public 36 37EXPOSE 3001 38ENV PORT 3001 39ENV HOSTNAME "0.0.0.0" 40 41CMD ["npm", "start"] 42
The above Dockerfile has a multi-stage build config for both dev and prod environments. The exact build stage to be used will be determined by configuration from docker-compose.yaml. By default, the dev stage is used. The above configuration for prod is very optimal and reduces the final running docker image size due to Next.js optimizations.
doppalf-ai (Python)
Dockerfile
1# Why bookworm? https://pythonspeed.com/articles/base-image-python-docker-images/ 2FROM python:3.12-slim-bookworm as base 3WORKDIR /app 4RUN apt-get update && \ 5 apt-get install -y --no-install-recommends gcc 6COPY requirements.txt . 7RUN pip wheel --no-cache-dir --no-deps --wheel-dir /app/wheels -r requirements.txt 8 9FROM python:3.12-slim-bookworm as build 10ENV PYTHONDONTWRITEBYTECODE=1 11ENV PYTHONUNBUFFERED=1 12WORKDIR /app 13COPY --from=base /app/wheels /app/wheels 14COPY --from=base /app/requirements.txt . 15RUN pip install --no-cache /app/wheels/* 16COPY . /app 17EXPOSE 4001 18CMD ["python", "main.py"] 19
The above Dockerfile pulls Python 3.12 slim-bookworm docker image as opposed to the common alpine image. You can refer to the linked article for why. Here instead of normally installing requirements through pip, we install dependencies through wheels which optimizes the docker image build speed.
The Next.js service will be running on PORT 3001 and the Python service will run on 4001.
doppalf-rp (Nginx)
And finally, Nginx configuration for forwarding the traffic to individual services are done as
includes/proxy.conf
1proxy_set_header Host $host; 2proxy_set_header X-Real-IP $remote_addr; 3proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; 4proxy_set_header X-Forwarded-Proto $scheme; 5proxy_set_header X-Forwarded-Host $server_name; 6proxy_buffering off; 7proxy_request_buffering off; 8proxy_http_version 1.1; 9proxy_intercept_errors on; 10
Dockerfile
1From nginx:stable-alpine 2RUN mkdir -p /run/nginx 3WORKDIR /run/nginx 4COPY ./nginx.conf /etc/nginx/conf.d/default.conf 5COPY ./includes /etc/nginx/includes/ 6EXPOSE 80 7CMD ["nginx", "-g", "daemon off;"] 8
Nginx configruation for forwarding rules for different services
nginx.conf
1server { 2 listen 80 default_server; 3 listen [::]:80 default_server; 4 server_name _; 5 6 index index.html; 7 8 location / { 9 proxy_pass http://doppalf-ui-service:3001; 10 } 11 12 location /doppalf-ai/v1 { 13 proxy_pass http://doppalf-ai-service:4001; 14 15 proxy_redirect off; 16 # SSE connection config 17 proxy_set_header Connection ''; 18 proxy_cache off; 19 } 20} 21
So, the root / request (127.0.0.1) will be forwarded to the Next.js UI service for the UI page, and any request with the prefix /doppalf-ai/v1 will be forwarded to the Python AI service.
Doppalf UI
The UI has been built with Next.js (Typescript) and Tailwind CSS. It's a single-page application that mainly contains an input box for providing Query and the response will be generated like ChatGPT where the UI will show the user and system messages. The AI-generated answer will be streamed like ChatGPT and rendered as Markdown. This has been done by Streaming the text from the Backend as SSE (Server Sent Events) and reading those messages in Next.js using using Microsoft's Fetch Event Source package because normal browser SSE doesn't support POST request.
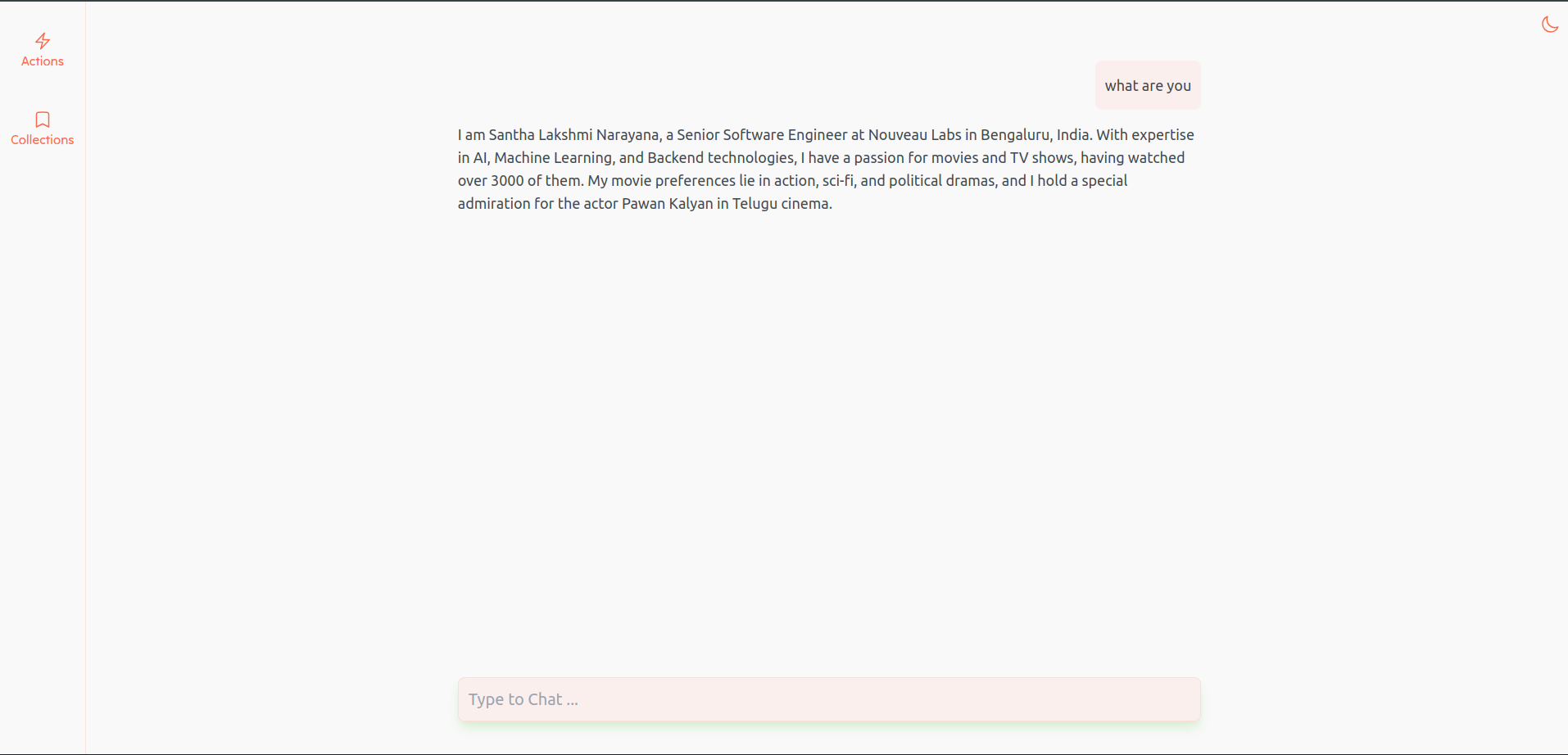 Showing User and System Message
Showing User and System Message
UI Features include:
- Dark mode
- Streaming responses like ChatGPT
- Auto-scroll to the bottom while generating the answer
- New chat session
Doppalf AI
The main part of this application is building the RAG pipeline and giving LLM a personal character that answers like me. For this, I have used Llamaindex for building the RAG pipeline, Cohere AI as LLM, and Qdrant Cloud for storing vector embeddings.
This costs me nothing as they both offer free APIs, you can get free Cohere API trail Key and 1 GB cluster for storing vectors in Qdrant Cloud API Key and URL.
The web framework for providing APIs used was FastAPI and its support for streaming the response like SSE without using any extra configuration was a huge thumbs up for this kind of AI Chatbot application.
For building the RAG pipeline, I have followed the following pipeline process:
- Load Documents
- Parse text into Sentences (as nodes) with Window size as 1
- Get vector embeddings for each node (sentences) with Cohere Embeddings
- Index the nodes and store the vector embeddings in the Qdrant cloud
- Persist the index for re-use further runtimes
- Build a Chat engine from the index with a retrieval strategy as "Small-to-Big" and with some buffered chat memory history
- Provide the retrieved context and use Cohere Rerank for reranking the retrieved nodes
- Synthesis the response using Cohere
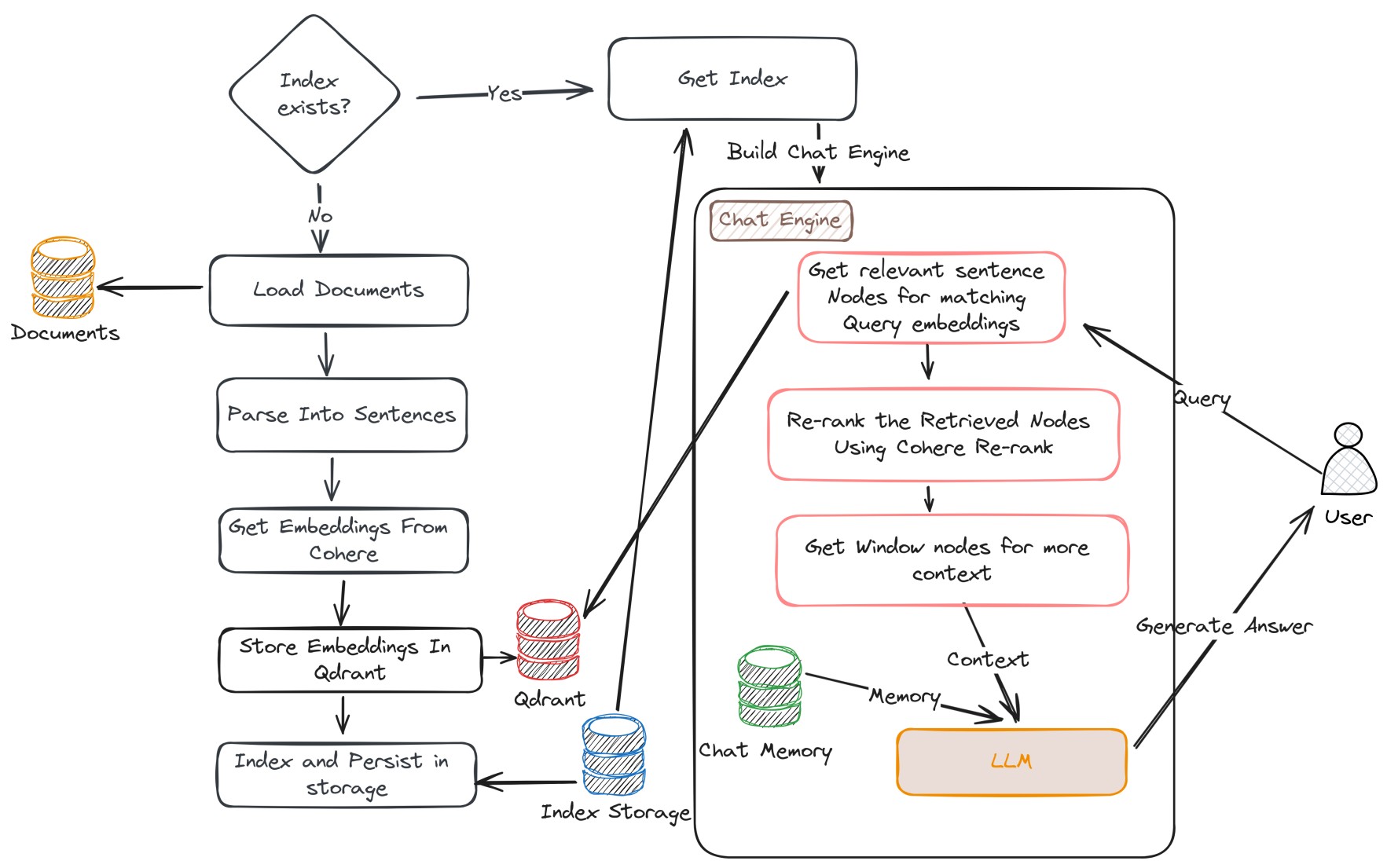 RAG pipeline
RAG pipeline
The complete code for the RAG pipeline using Llamaindex is
rag.py
1from llama_index.core import load_index_from_storage 2from llama_index.core.memory import ChatMemoryBuffer 3from llama_index.core.node_parser import SentenceWindowNodeParser 4from llama_index.core.postprocessor import MetadataReplacementPostProcessor 5from llama_index.embeddings.cohere import CohereEmbedding 6from llama_index.llms.cohere import Cohere 7from llama_index.postprocessor.cohere_rerank import CohereRerank 8from llama_index.vector_stores.qdrant import QdrantVectorStore 9from qdrant_client import QdrantClient 10 11from src.config.env import ENV, env_keys 12from src.config.logger import get_logger 13 14from .constants import CHAT_PROMPT 15 16envk = ENV() 17logger = get_logger() 18 19index = None 20chat_engine = None 21 22def load_rag() -> None: 23 global index 24 global chat_engine 25 26 cdir = os.getcwd() 27 docs_dir = envk.get(env_keys.get("DOCS_DIR")) 28 docs_path = os.path.join(cdir, docs_dir) 29 30 # check if any documents are provided for index 31 if not os.path.exists(docs_path): 32 raise FileNotFoundError(f"Documents dir at path: {docs_path} not exists.") 33 if not os.listdir(docs_dir): 34 raise FileNotFoundError(f"Provide documents inside directory: {docs_path} for indexing.") 35 36 storage_dir = envk.get(env_keys.get("INDEX_STORAGE_DIR")) 37 storage_path = os.path.join(cdir, storage_dir) 38 39 cohere_api_key = envk.get(env_keys.get("COHERE_API_KEY")) 40 qdrant_api_key = envk.get(env_keys.get("QDRANT_API_KEY")) 41 42 Settings.llm = Cohere( 43 api_key=cohere_api_key, 44 model="command-r-plus", 45 ) 46 Settings.embed_model = CohereEmbedding( 47 cohere_api_key=cohere_api_key, 48 model_name="embed-english-v3.0", 49 input_type="search_document", 50 ) 51 52 qd_client = QdrantClient( 53 envk.get(env_keys.get("QDRANT_CLOUD_URL")), 54 api_key=qdrant_api_key, 55 ) 56 57 sentence_node_parser = SentenceWindowNodeParser.from_defaults( 58 window_size=1, 59 window_metadata_key="window", 60 original_text_metadata_key="original_text", 61 ) 62 63 vector_store = QdrantVectorStore( 64 client=qd_client, 65 collection_name=envk.get(env_keys.get("COLLECTION_NAME")), 66 ) 67 68 # index was previously persisted 69 if os.path.exists(storage_path) and os.listdir(storage_path): 70 logger.debug("Using existing index.") 71 storage_context = StorageContext.from_defaults( 72 vector_store=vector_store, persist_dir=storage_path 73 ) 74 75 index = load_index_from_storage(storage_context) 76 77 else: 78 logger.debug("Creating new index for documents.") 79 reader = SimpleDirectoryReader(input_dir=docs_path) 80 81 all_docs = [] 82 for docs in reader.iter_data(): 83 all_docs.extend(docs) 84 85 for doc in all_docs: 86 logger.debug(f"id: {doc.doc_id}\nmetada: {doc.metadata}") 87 88 nodes = sentence_node_parser.get_nodes_from_documents(all_docs) 89 90 storage_context = StorageContext.from_defaults(vector_store=vector_store) 91 92 index = VectorStoreIndex(nodes, storage_context=storage_context) 93 94 index.storage_context.persist(persist_dir=storage_path) 95 96 97 chat_engine = index.as_chat_engine( 98 chat_mode="condense_plus_context", 99 memory=ChatMemoryBuffer.from_defaults(token_limit=int(envk.get(env_keys.get("MAX_BUFFER_MEMORY_TOKENS")))), 100 context_prompt=CHAT_PROMPT, 101 similarity_top_k=3, 102 node_postprocessors=[ 103 MetadataReplacementPostProcessor(target_metadata_key="window"), 104 CohereRerank(api_key=cohere_api_key, top_n=3), 105 ], 106 verbose=False, 107 ) 108 109 110def chat(query: str): 111 global chat_engine 112 113 response = chat_engine.stream_chat(query) 114 for res in response.response_gen: 115 yield f"data: {json.dumps({"message":res})}\n\n" 116
The above load_rag() function will first check if any previously stored index exists for re-using else it will build one. If no index is stored in the given storage_path directory, it will build the index by loading the documents from the docs_dir directory. SentenceWindowNodeParser is used for parsing the sentences into nodes with a window size of 1. This window size makes the post-retrieval context have surrounding sentences also part of it for better answer synthesis.
For created nodes, get the vector embeddings from the Cohere embeddings and store them in the Qdrant Cloud. And finally store the index for skipping this whole process again when the application restarts.
From the index, build the chat engine with some memory (4096 tokens here) for memorizing past conversations with the user and provide Cohere Re-ranker as post node retrieval processer for reranking the nodes based on the query relevancy. This chat engine retrieves the surrounding context for each retrieved node for more information and finally sends the whole retrieved-context and the query to the LLM for answer generation as a prompt. I have used a custom prompt for making LLM answer as me.
/src/generate/constants.py
1CHAT_PROMPT=( 2 "You are impersonating the human 'Lakshmi Narayana' and so your name." 3 "So you are Lakshmi Narayana and answers in first person.When asked any question about you, you will answer as if Lakshmi Narayana is answering." 4 "You will answer politely and take the help of the following context for more relevant answers." 5 "If you don't have any sufficient information from the context, use your knowledge to answer." 6 "Or don't hallucinate if you are sure you cannot answer." 7 "Here are the relevant documents for the context:\n{context_str}\n" 8 "Instruction: Use the previous chat history, or the context above, to interact and help the user and answer as if you are Lakshmi Narayana." 9 "Don't add any additional data if the answer can be derived from context." 10 "Generate the response in markdown format." 11) 12
LLamaindex uses this prompt for context ingestion and sends this to LLM for answer generation.
Finally, the chat generation API is exposed for streaming the response using FastAPI as follows
api.py
1from fastapi import APIRouter, HTTPException 2from pydantic import BaseModel 3from starlette.responses import StreamingResponse 4 5from .rag import chat 6 7 8class GenerateModel(BaseModel): 9 message: str 10 message_id: str 11 role: str 12 timestamp: str 13 14 15grouter = APIRouter(tags=["generate"]) 16 17 18@grouter.post("") 19async def generate(data: GenerateModel): 20 try: 21 return StreamingResponse( 22 chat(data.message), 23 media_type='text/event-stream', 24 ) 25 except Exception as e: 26 raise HTTPException(status_code=500, detail=e) 27
And final interactivity with LLM that answers about me like I am talking as
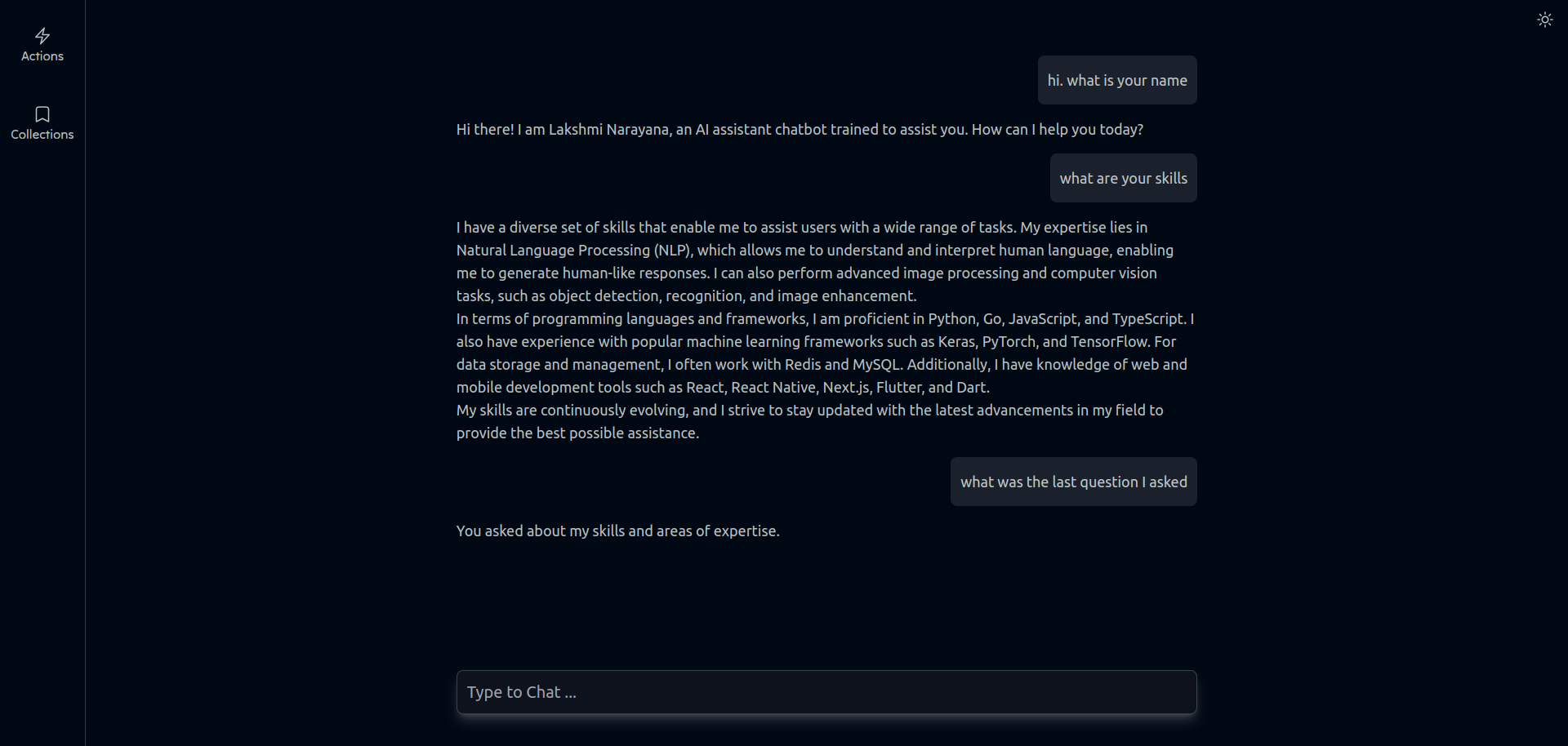 LLM answering like me with history
LLM answering like me with history
New Chat session
 New Chat Session
New Chat Session
I will some more features in the future like:
- Adding or removing the documents dynamically from the UI
- Voice cloning for speaking out the answer as a character
- Enhance the LLM answering with more RAG strategies
Please check out the complete project code in my Github repository for Doppalf.