
Published on: Mar 6, 2024
Asynchronous or Concurrency Patterns in Python with Asyncio
Most software development tasks require an asynchronous way of handling things like running background tasks, processing multiple tasks at a time, applying the same operations on huge data, distributing tasks to free workers, etc. In this blog, we will see how can we achieve some of these patterns with Python.
Before delving into the concept, the most important thing we need to understand is concurrency vs parallelism. Concurrency is about handling multiple tasks at a time and this handling might be in parallel or not. Whereas parallelism is about doing multiple tasks parallelly/simultaneously at a time. Parallelism can be termed as concurrency but not vice-versa.
In my earlier blog posts about Super Fast Python: Multiprocessing, I have described how can achieve parallelism with Python.
One can ask, in parallelism, if we can do multiple things at a time, why do we need to focus on concurrency at all? The answer to this question simply depends on the program language in the discussion. Some program languages like C/C++ are built to directly use multiple cores/vCPUs of the host machine for parallelism, while other languages like Golang can still utilize multiple cores but with concurrency, not parallel. Both of these types of languages can do both concurrency and parallelism very smoothly. But we have a special child like Python, whose creators put so many restrictions (which are thoughtful at creation) to be a better resource utiliser. GIL in Python makes the Python interpreter run only one thread at a time and cannot multiplex the multiple threads to multiple cores. I have already discussed this in my previous post about Why Python is Slow.
To utilize multiple cores, we have to create at least one process per core. The creation and memory management of the process is time-consuming and comes with its overheads. So, a general rule of thumb is to use multi-programming for CPU-intensive tasks, and I/O bound tasks like network calls, and reading from disk are handled concurrently with threads. As we can use multi-threading in Python, creating and managing a huge number of threads is not optimal in Python or any high-level language. The solution to create and manage huge numbers of thread-like objects say in thousands or 100s of thousands, we can use Co-routines which can be termed as virtual threads or small threads whose memory footprint is very minimal compared to threads. And we can spawn thousands of these in a few microseconds.
Coroutines are part of core Python and are handled with an in-built package called asyncio
The goal of this article is to demonstrate some concurrency patterns rather than learning about coroutines. So, it's expected to have some basic background with asyncio.
In the following sections, we cover the two most used concurrency patterns:
- Background tasks with Ticker
- WorkerPool pattern
- Pipeline or Chain processing
Ticker & Background tasks
Let's say we have a stream of data coming and stored in some data sources like Database, Redis, or in the Cloud. And we want to analyze that data periodically let's say every 1 day and send an email notification to the customers with the analyzed report. This is a basic CRON job that we execute in Linux.
If you don't know what the is ticker, it is a kind of background task where the program will be notified for every time interval that we need to do some task. Tickers are all over any periodic notification or job updates.
We will use a ticker for our coroutine to come into the foreground and call a callback that it receives with callback arguments. Let's look at the following ticker class
ticker.py
1from threading import Event, Thread 2from typing import Any, Callable, Optional 3 4class Ticker(Thread): 5 def __init__( 6 self, 7 is_daemon: bool, 8 tick_period: int, 9 callback: Callable, 10 **cbkwargs: Optional[Any] 11 ): 12 Thread.__init__(self) 13 self.daemon = is_daemon 14 self.tick_period = tick_period 15 self.task_kill_event = Event() 16 self.callback = callback 17 self.cbkwargs = cbkwargs 18 19 def kill(self): 20 self.task_kill_event.set() 21 22 def run(self): 23 while True: 24 is_killed = self.task_kill_event.wait(self.tick_period) 25 if is_killed: 26 print("Exiting ticker.") 27 break 28 29 # call the callback 30 try: 31 self.callback(**self.cbkwargs) 32 except Exception as e: 33 print(f"Exception for callback: {e}") 34
This class inherits the Thread class to implement custom thread functionality. In the constructor, we pass the is_daemon flag that makes the current thread run as a daemon or not. Usually for background tasks that do not stick to the application lifecycle, they are not meant to be daemon. And other params like tick_period which says the time interval for the ticker, callback is a callback function, and cbkwargs are callback key arguments to pass to this callback function. We will speak about self.task_kill_event = Event() later.
This class has two methods kill and run where run is an overridden Thread class function.
threading.Event() object is used for communication between threads. It's simply a boolean flag that one thread signals the other thread that listens to this event object states. We use an event object to signal for the background task to exit. This is what the kill function is. If we call this function, it will set the event to be True signaling the listing thread.
The overriding run method is a classic implementation of a background running thread, it will run in a loop until it receives the is_killed to be True which we set by calling kill. self.task_kill_event.wait(self.tick_period) is where the magic happens. Here we will wait for the specified ticker period for that event to be set. After the specified interval period, if we don't receive the event signal, the is_killed will be False, and we will call the callback with the keyword arguments.
Why don't we use a simple thread.sleep for sleeping in the background? Let's say, that while waiting for a ticker period, we get the event signal, then we have to right away exit the thread. For example, if the ticker period is for 10 seconds, and while in the 6th second, we get the signal, we will exit there instead of waiting for the other 4 seconds. This can't be achieved with thread sleep. This is very useful if we are running larger ticker periods let's for days or weeks.
Let's look at how we can run this ticker thread for every time inteval.
ticker_example.py
1import asyncio 2from ticker import Ticker 3 4process_called = 0 5def process(task_for=""): 6 global process_called 7 process_called += 1 8 print("process called for: ", process_called, " times") 9 10async def stop_ticker(kill_func: Callable, after_time: int): 11 await asyncio.sleep(after_time) 12 kill_func() 13 # call any cleanup functions for graceful exiting 14 await asyncio.sleep(1) 15 16if __name__=="__main__": 17 cbkargs = {"task_for": "data-pre-process"} 18 ticker = Ticker(True, 3, process, **cbkargs) 19 ticker.start() 20 21 ev_loop = asyncio.get_event_loop() 22 ev_loop.run_until_complete(stop_ticker(ticker.kill, 7)) 23
Output
1process called for: 1 times 2process called for: 2 times 3Exiting ticker. 4
In the above example, we have imported the Ticker class and defined a function process which we pass as a callback to this ticker. This function will be called for after every ticker period and this is where we do any periodic processing like sending notifications.
The line ticker = Ticker(True, 3, process, **cbkargs) initializes the ticker with 3 second time interval. We have defined another function stop_ticker which we will use to kill the ticker after some time. The stop ticker function will wait for some time (7 seconds here) and kill the ticker.
As we can see in the output, the ticker called the callback every 3 seconds and got stopped by the parent thread which is our main thread here through stop_ticker function.
This is a very effective way of defining a ticker in Python with a simple thread mechanism. Now we will see how we can define a worker pool for processing multiple jobs by multiple workers concurrently.
Worker pool/Job queue pattern
We can define worker pool concurrency patterns with threads alone using multi-threading. But there are limitations with threads, like:
- Threads are synchronous, meaning when a thread is paused it blocks the execution also, leaving other threads for starvation
- we cannot create a huge number of threads due to various reasons like memory, context switching, etc.
So, we can use a coroutine to do this job because we can have an asynchronous way of doing things if have to call any API or wait to load the huge dataset, we can pause the current coroutine and let others claim the CPU. As Python is single-threaded, meaning only 1 thread can run at a time, this un-blocking way of organizing your tasks makes your Python code efficient and performant. And we can create thousands of coroutines in quick time and they occupy very little memory.
The worker pool pattern is a simple and the most widely used concurrency pattern for distributing multiple tasks or jobs (n-jobs) to multiple workers (m-workers). Usually n >= m. In this pattern, we have a list of jobs to be processed, and they are to be read from a static queue or a dynamic stream. And we have to distribute those jobs to idle workers who take the job and process it. Worker may or may not return the result based on the type of the Job. Idle workers are very hungry and they compete with other idle workers to take the incoming Job or un-attended Job.
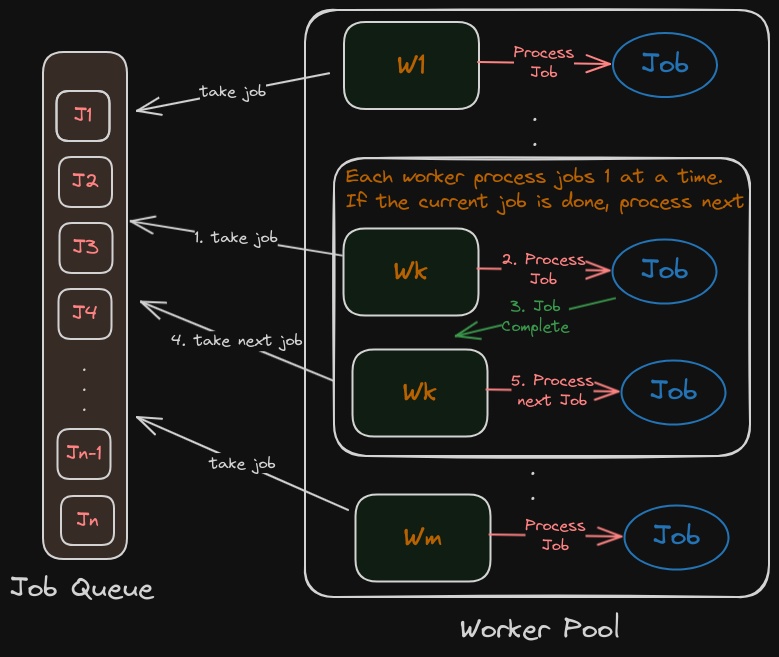 Worker pool with Job Queue. Each idle worker takes one job at a time and processes the Job. After the job is complete, the worker will continue to take any un-attended Job.
Worker pool with Job Queue. Each idle worker takes one job at a time and processes the Job. After the job is complete, the worker will continue to take any un-attended Job.
As in the above image, the jobs are stored in some data structure say a Job Queue, and we have a pool of workers. We usually incorporate a scheduler/distributor to assign the Jobs to idle Workers. So, at a time, if we have m workers, then we can process m Jobs concurrently. If we can access multiple cores, then these Jobs are processed parallelly like in Golang. Because Python has some overhead for forking multiple processes, we will stick to single-threaded concurrent execution of Jobs by multiple Workers. The following code implements this worker pool pattern where we have to process the n-number of Jobs.
worker_pool.py
1import asyncio 2from asyncio.queues import Queue 3from threading import Thread 4from typing import Any, Callable, List 5 6 7class WorkerPool(Thread): 8 def __init__( 9 self, 10 is_daemon: bool, 11 jobs: List[Any], 12 n_workers: int, 13 callback: Callable[[List[Any]], None], 14 ): 15 Thread.__init__(self) 16 self.daemon = is_daemon 17 self.jobs = jobs 18 19 self.event_loop = asyncio.new_event_loop() 20 asyncio.set_event_loop(self.event_loop) 21 22 self.job_queue = Queue() 23 self.n_workers = n_workers 24 self.callback = callback 25 26 async def distribute(self, w_name: str): 27 while self.job_queue.qsize() > 0: 28 job = await self.job_queue.get() 29 try: 30 # call the callback with the Job details 31 await self.callback(job) 32 except Exception as e: 33 raise Exception(f"Exception for callback: {e}") 34 finally: 35 # mark the current job as done 36 # will get an exception if it's already done by the current worker or any other worker 37 try: 38 self.job_queue.task_done() 39 except ValueError: 40 print(f"{w_name}: Task already done.") 41 return 42 43 async def job_wp(self): 44 # add jobs to the job-queue. 45 # this job queue can be concurrently accessed by multiple workers 46 for i in range(len(self.jobs)): 47 await self.job_queue.put(self.jobs[i]) 48 49 tasks = [] 50 51 # create multiple workers that take un-attended jobs from the job queue 52 # and continuously process them until all jobs are executed 53 for i in range(self.n_workers): 54 tasks.append(self.distribute(f"Worker: {i+1}")) 55 56 await asyncio.gather(*tasks) 57 58 def run(self): 59 try: 60 self.event_loop.run_until_complete(self.job_wp()) 61 except Exception as e: 62 print(f"Error distributing jobs: {e}") 63 finally: 64 self.event_loop.close() 65
Here, we extend the Thread class to execute WorkerPool in a separate thread. The constructor takes the list of job items, n_workers for how many workers to spawn, and a callback function to call with the job detail.
WorkerPool class defines two methods job_wp and distribute. job_wp creates a JobQueue with all jobs and also creates multiple workers each with a name Worker: i where i is ith worker. This function will wait for all workers to complete processing all Jobs.
distribute function takes the unattended job and calls the callback with job details as parameters to the callback function. We can also extend this to pass arguments. After executing the job, we finally mark that job as done.
Example of processing Jobs by multiple workers:
worker_pool_example.py
1from random import randint 2from time import time 3from worker_pool import WorkerPool 4 5async def process_job(job_detail: Any): 6 time_to = randint(1, 4) 7 print("Processing job:", job_detail, "will take:", time_to, "seconds") 8 await asyncio.sleep(time_to) 9 print("Completed job:", job_detail) 10 11if __name__=="__main__": 12 wp = WorkerPool(True, list(range(1, 11)), 3, process_job) 13 atime = time() 14 wp.start() 15 wp.join() 16 print("time taken:", str(int(time()-atime)) + "s") 17
Here, we initialize the WorkerPool class with 10 jobs and 3 workers along with a callback process_job. This process_job function might take any of [1, 4] seconds to complete.
Output
1Processing job: 1 will take: 3 seconds 2Processing job: 2 will take: 1 seconds 3Processing job: 3 will take: 1 seconds 4Completed job: 2 5Processing job: 4 will take: 4 seconds 6Completed job: 3 7Processing job: 5 will take: 4 seconds 8Completed job: 1 9Processing job: 6 will take: 3 seconds 10Completed job: 4 11Processing job: 7 will take: 1 seconds 12Completed job: 5 13Processing job: 8 will take: 1 seconds 14Completed job: 6 15Processing job: 9 will take: 2 seconds 16Completed job: 7 17Processing job: 10 will take: 1 seconds 18Completed job: 8 19Completed job: 10 20Completed job: 9 21time taken: 8s 22
With this asynchronous processing of Jobs, we have processed all the jobs whose collective processing time requires 21 seconds in 8 seconds thanks to asyncio whereas with un-optimized multi-threading, it might take the same 21 seconds due to threads blocking nature.
Pipeline or Chain processing
Pipeline pattern or Chain processing is a simple concurrency pattern of executing the multiple jobs consecutively where the input for the current job is the output of the previous job. For example, let's say we have to analyze incoming data about customer ratings (scale: 1-5) for our service. And we have to do the following steps:
- Analyse the feedback
- If the rating is below 3, we have to store this rating for later analyses
- Later generate the thank you message for the customer
- Finally, based on the preference notification channel (Email or SMS) we will send a thank you message.
This whole process needs a couple of logical decisions to take at each level of processing. Based on multi-logic flow, we can divide the above process into small functions and we execute each function sequentially based on where the next function call is decided based on the current input data.
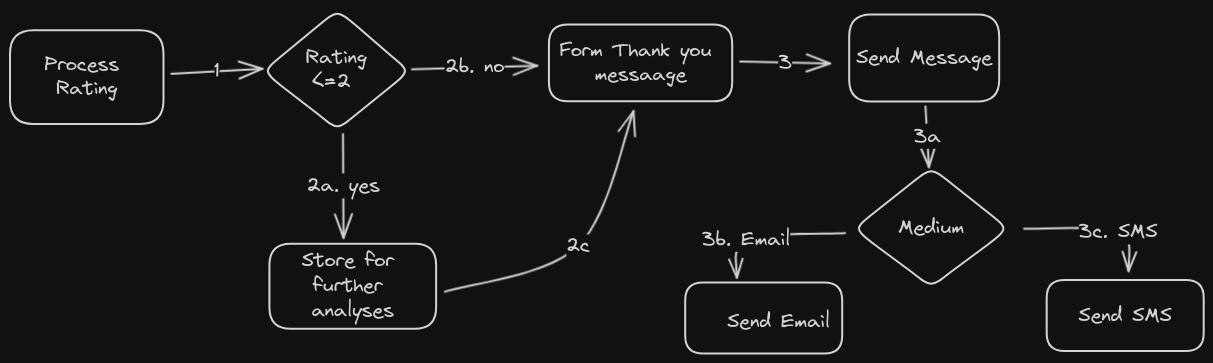 Processing pipeline/flow
Processing pipeline/flow
If we have multiple customer ratings to be analyzed we can combine the WorkerPool pattern with this Pipeline pattern.
pipeline.py
1import asyncio 2import random 3from worker_pool import WorkerPool 4 5commuincation_type = ["email", "sms"] 6 7async def process_rating(job: list): 8 rating, user, idx = job 9 print(f"1. processing rating, for item: {idx}, rating: {rating} by user: {user}") 10 # some processing 11 await asyncio.sleep(1) 12 if rating <= 2: 13 await store_for_analyses(rating, idx) 14 else: 15 await form_thankyou_message(user, idx) 16 17async def store_for_analyses(rating: int, idx: int): 18 print(f"1a. storing for analyses, for item: {idx}") 19 # store in some datastore 20 await asyncio.sleep(1) 21 22async def form_thankyou_message(user: str, idx: int): 23 print(f"2. forming thank-you message, for item: {idx}") 24 # a DB call to fetch the user details 25 await asyncio.sleep(1) 26 27 # communication medium may be {email, sms} 28 cs = random.choices(commuincation_type, weights=[0.5, 0.5], k=1)[0] 29 30 match cs: 31 case "email": 32 await send_email_message(user, idx) 33 case "sms": 34 await send_sms_message(user, idx) 35 case _: 36 return 37 38async def send_email_message(user: str, idx: int): 39 print(f"2a. sending email message, for item: {idx}, for user: {user}") 40 # sendinig might take time 41 await asyncio.sleep(1) 42 43async def send_sms_message(user: str, idx: int): 44 print(f"2b. sending sms message, for item: {idx}, for user: {user}") 45 # sendinig might take time 46 await asyncio.sleep(1) 47 48 49if __name__=="__main__": 50 # create ratings, users, and items 51 n = 10 52 ratings = random.choices([1, 2, 3, 4, 5], weights=[0.25, 0.25, 0.15, 0.15, 0.2], k=n) 53 items = list(range(1, n+1)) 54 users = list(map(lambda x: f"User {x}", items)) 55 56 jobs = [] 57 for i in range(n): 58 jobs.append([ratings[i], users[i], items[i]]) 59 60 wp = WorkerPool(True, jobs, 3, process_rating) 61 wp.start() 62 wp.join() 63
Here we define a list of functions that are depicted in the image above. Each function will take input from the previous function and apply its decision logic to call which function next.
In the example, we have created 10 rating items to be processed by 3 workers. The output of the processing is
Output
11. processing rating, for item: 1, rating: 4 by user: User 1 21. processing rating, for item: 2, rating: 3 by user: User 2 31. processing rating, for item: 3, rating: 3 by user: User 3 42. forming thank-you message, for item: 1 52. forming thank-you message, for item: 2 62. forming thank-you message, for item: 3 72b. sending sms message, for item: 1, for user: User 1 82a. sending email message, for item: 2, for user: User 2 92a. sending email message, for item: 3, for user: User 3 101. processing rating, for item: 4, rating: 2 by user: User 4 111. processing rating, for item: 5, rating: 5 by user: User 5 121. processing rating, for item: 6, rating: 4 by user: User 6 131a. storing for analyses, for item: 4 142. forming thank-you message, for item: 5 152. forming thank-you message, for item: 6 161. processing rating, for item: 7, rating: 5 by user: User 7 172a. sending email message, for item: 5, for user: User 5 182b. sending sms message, for item: 6, for user: User 6 192. forming thank-you message, for item: 7 201. processing rating, for item: 8, rating: 5 by user: User 8 211. processing rating, for item: 9, rating: 1 by user: User 9 222b. sending sms message, for item: 7, for user: User 7 232. forming thank-you message, for item: 8 241a. storing for analyses, for item: 9 251. processing rating, for item: 10, rating: 5 by user: User 10 262b. sending sms message, for item: 8, for user: User 8 272. forming thank-you message, for item: 10 282b. sending sms message, for item: 10, for user: User 10 29
Custom coroutine
If you want an asynchronous function in a separate thread with the async capabilities, we can run a coroutine as follows
coroutine.py
1import asyncio 2from threading import Thread 3from typing import Any, Callable, List, Optional 4 5class CustomCoroutine(Thread): 6 def __init__( 7 self, 8 is_daemon: bool, 9 callback: Callable[[List[Any]], None], 10 **cbkwargs: Optional[Any] 11 ): 12 Thread.__init__(self) 13 self.daemon = is_daemon 14 self.event_loop = asyncio.new_event_loop() 15 asyncio.set_event_loop(self.event_loop) 16 self.callback = callback 17 self.cbkwargs = cbkwargs 18 19 async def callback(self) -> None: 20 try: 21 await self.callback(**self.cbkwargs) 22 except Exception as e: 23 print(f"Error calling callback: {e}") 24 25 def run(self) -> None: 26 try: 27 self.event_loop.run_until_complete(self.callback()) 28 finally: 29 self.event_loop.close() 30
I hope the above concurrency patterns give you some understanding of organizing your Python code for better performance and optimization. Other concurrency patterns that are worth noting are:
- Monitor pattern: n number of threads waiting on some condition to be true, if the condition is not true, those threads need to be in a sleep state and pushed to the wait queue, and they have to be notified when the condition becomes true.
- Double Checked locking: for creating concurrent objects. (Ex: Singleton design pattern)
- Barrier pattern: All concurrently executing threads must wait for others to complete and wait at a point called barrier.
- Reactor pattern: In an event-driven system, a service handler accepts events from multiple incoming requests and demultiplexes to respective non-blocking handlers.